Main
其实AI量特别高,但是令人感动的是这个代码第一次运行没有报错。
图片预览
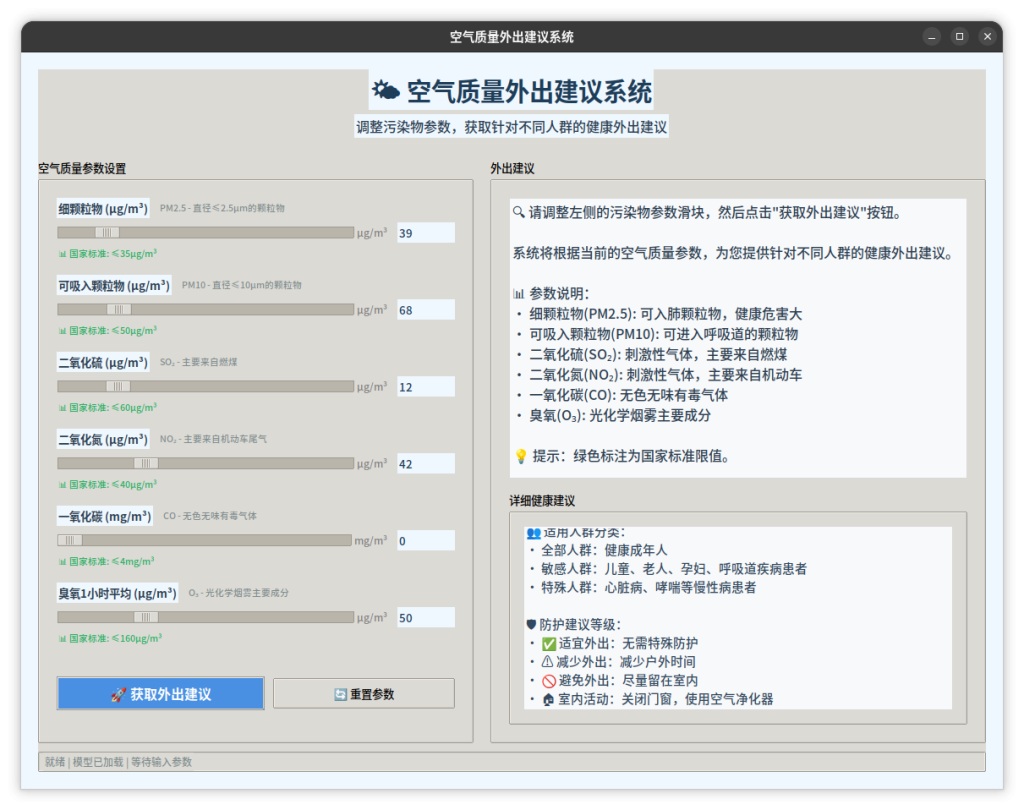
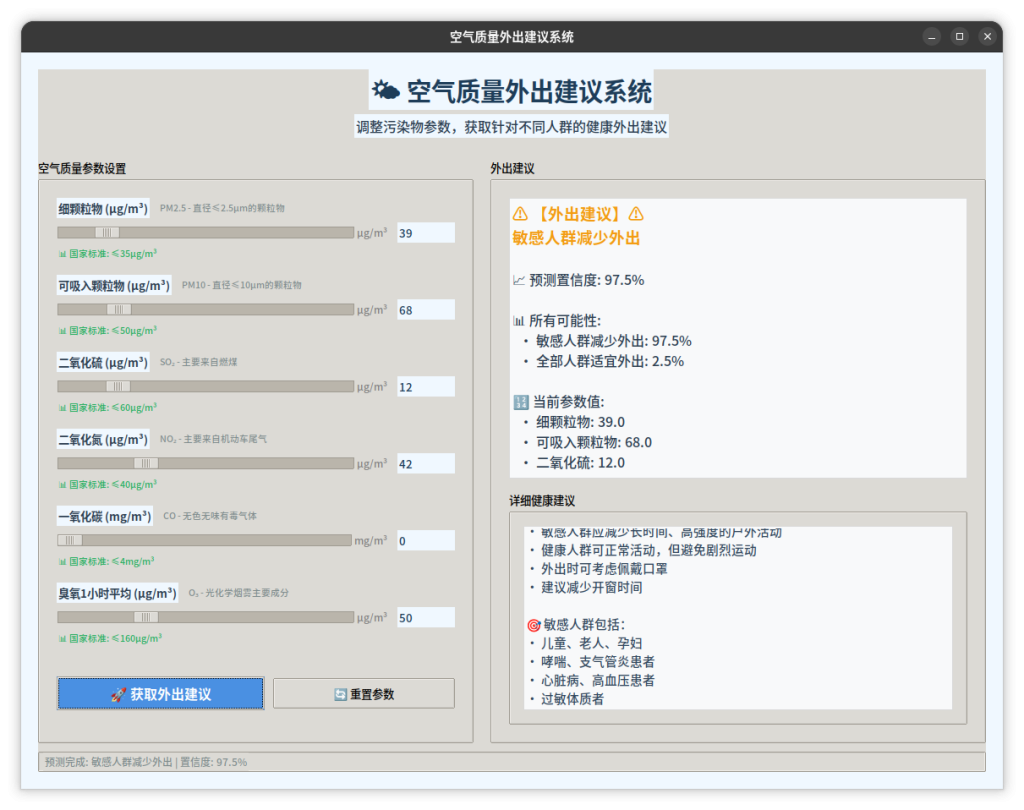
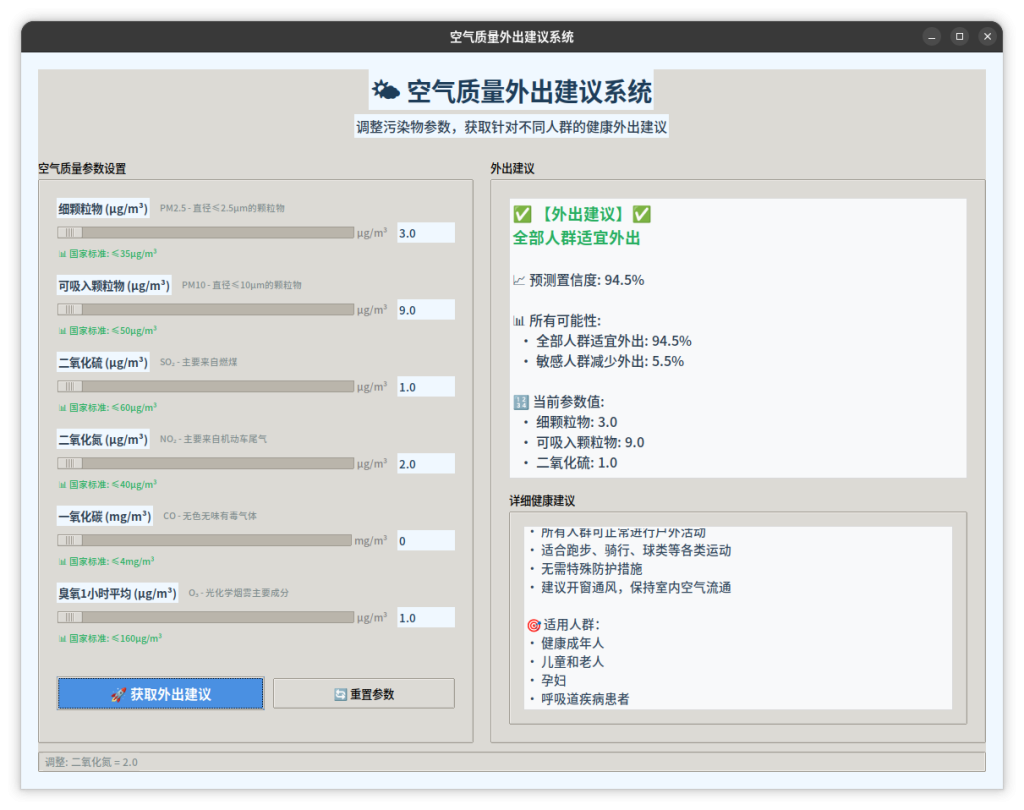
文件分享
为了防止本站被刷爆流量,故放出第三方云盘下载渠道:
https://www.123865.com/s/qPh5Vv-LrdO?pwd=1145#
主要代码展示(air_quality_Wenzhou):
train_model.py
"""
空气质量外出建议模型训练脚本
训练完成后会生成 models/air_quality_model.pkl
"""
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib
import seaborn as sns
import matplotlib.pyplot as plt
import os
import json
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Noto Sans CJK JP']
plt.rcParams['axes.unicode_minus'] = False
class AirQualityModelTrainer:
def __init__(self, data_path='data/cata_6716.csv'):
"""初始化模型训练器"""
self.data_path = data_path
self.df = None
self.X = None
self.y = None
self.label_encoder = None
self.scaler = None
self.model = None
def load_and_preprocess(self):
"""步骤1:加载和预处理数据"""
print("=== 步骤1: 加载和预处理数据 ===")
# 1.1 读取数据(使用GBK编码处理中文)
try:
self.df = pd.read_csv(self.data_path, encoding='gbk')
except:
# 尝试其他编码
self.df = pd.read_csv(self.data_path, encoding='utf-8')
print(f"✓ 数据加载成功: {self.df.shape[0]} 行, {self.df.shape[1]} 列")
print(f"✓ 数据时间范围: {self.df['年份'].min()}年 至 {self.df['年份'].max()}年")
print(f"✓ 城市: {self.df['城市名'].iloc[0] if '城市名' in self.df.columns else '未指定'}")
# 1.2 检查并选择特征列
feature_columns = [
'细颗粒物', # PM2.5
'可吸入颗粒物', # PM10
'二氧化硫', # SO2
'二氧化氮', # NO2
'一氧化碳', # CO
'臭氧1小时平均' # O3
]
# 检查特征是否存在
available_features = [col for col in feature_columns if col in self.df.columns]
if len(available_features) < len(feature_columns):
print(f"⚠ 警告: 部分特征不存在,使用可用特征: {available_features}")
# 1.3 创建特征矩阵
self.X = self.df[available_features].copy()
print(f"✓ 使用特征: {available_features}")
# 1.4 创建目标变量(人群类别)
print("\n=== 创建目标变量 ===")
self.df['人群类别'] = self.df.apply(self._create_crowd_label, axis=1)
# 1.5 编码目标变量
self.label_encoder = LabelEncoder()
self.y = self.label_encoder.fit_transform(self.df['人群类别'])
# 显示类别分布
label_counts = pd.Series(self.y).value_counts().sort_index()
label_dist = pd.DataFrame({
'编码': range(len(self.label_encoder.classes_)),
'人群类别': self.label_encoder.classes_,
'样本数量': label_counts.values
})
print("目标变量分布:")
print(label_dist.to_string(index=False))
# 1.6 特征标准化
self.scaler = StandardScaler()
self.X_scaled = self.scaler.fit_transform(self.X)
return self.X_scaled, self.y, available_features
def _create_crowd_label(self, row):
"""根据AQI和污染物浓度创建人群类别标签"""
aqi = row['空气质量指数'] if '空气质量指数' in row else 50
# 基于中国空气质量标准和健康建议
if aqi <= 50:
return '全部人群适宜外出'
elif aqi <= 100:
# 在良的范围内,根据主要污染物进一步细分
pm25 = row['细颗粒物'] if '细颗粒物' in row else 35
o3 = row['臭氧1小时平均'] if '臭氧1小时平均' in row else 100
if pm25 > 35 or o3 > 100:
return '敏感人群减少外出'
else:
return '全部人群适宜外出'
elif aqi <= 150:
return '敏感人群避免外出'
elif aqi <= 200:
return '所有人群减少外出'
elif aqi <= 300:
return '儿童老人避免外出'
else:
return '室内活动为佳'
def train_model(self, test_size=0.2, random_state=42):
"""步骤2:训练模型"""
print("\n=== 步骤2: 训练模型 ===")
# 2.1 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
self.X_scaled, self.y,
test_size=test_size,
random_state=random_state,
stratify=self.y
)
print(f"✓ 训练集: {X_train.shape[0]} 样本")
print(f"✓ 测试集: {X_test.shape[0]} 样本")
# 2.2 训练随机森林模型
print("训练随机森林模型中...")
self.model = RandomForestClassifier(
n_estimators=200,
max_depth=15,
min_samples_split=5,
min_samples_leaf=2,
random_state=random_state,
class_weight='balanced',
n_jobs=-1,
verbose=0
)
self.model.fit(X_train, y_train)
print("✓ 模型训练完成")
# 2.3 模型评估
y_pred = self.model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"\n=== 模型评估结果 ===")
print(f"准确率: {accuracy:.4f}")
print("\n详细分类报告:")
print(classification_report(y_test, y_pred,
target_names=self.label_encoder.classes_))
# 2.4 特征重要性分析
feature_importance = pd.DataFrame({
'特征': self.X.columns,
'重要性': self.model.feature_importances_
}).sort_values('重要性', ascending=False)
print("\n特征重要性排序:")
print(feature_importance.to_string(index=False))
# 2.5 可视化特征重要性
self._plot_feature_importance(feature_importance)
# 2.6 生成混淆矩阵
self._plot_confusion_matrix(y_test, y_pred)
return accuracy, X_test, y_test, y_pred
def _plot_feature_importance(self, feature_importance):
"""可视化特征重要性"""
plt.figure(figsize=(10, 6))
bars = plt.barh(feature_importance['特征'], feature_importance['重要性'],
color=plt.cm.viridis(np.linspace(0.3, 0.9, len(feature_importance))))
plt.xlabel('特征重要性', fontsize=12)
plt.title('污染物特征重要性排序', fontsize=14, fontweight='bold')
plt.gca().invert_yaxis() # 最重要的显示在最上面
# 添加数值标签
for bar in bars:
width = bar.get_width()
plt.text(width + 0.001, bar.get_y() + bar.get_height()/2,
f'{width:.3f}', ha='left', va='center', fontsize=10)
plt.tight_layout()
plt.savefig('feature_importance.png', dpi=300, bbox_inches='tight')
print("✓ 特征重要性图已保存: feature_importance.png")
plt.close()
def _plot_confusion_matrix(self, y_test, y_pred):
"""绘制混淆矩阵"""
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=self.label_encoder.classes_,
yticklabels=self.label_encoder.classes_)
plt.title('混淆矩阵', fontsize=14, fontweight='bold')
plt.xlabel('预测标签', fontsize=12)
plt.ylabel('真实标签', fontsize=12)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig('confusion_matrix.png', dpi=300, bbox_inches='tight')
print("✓ 混淆矩阵已保存: confusion_matrix.png")
plt.close()
def save_model(self, model_path='models/air_quality_model.pkl'):
"""步骤3:保存模型和相关数据"""
print("\n=== 步骤3: 保存模型 ===")
# 3.1 创建保存目录
os.makedirs('models', exist_ok=True)
# 3.2 准备保存的数据
model_data = {
'model': self.model,
'label_encoder': self.label_encoder,
'scaler': self.scaler,
'feature_columns': list(self.X.columns),
'feature_importance': pd.DataFrame({
'特征': self.X.columns,
'重要性': self.model.feature_importances_
}).sort_values('重要性', ascending=False).to_dict('records'),
'class_descriptions': {
0: '全部人群适宜外出 - 空气质量优,适合所有户外活动,包括跑步、骑行等剧烈运动',
1: '敏感人群减少外出 - 空气质量良,敏感人群应减少长时间户外活动',
2: '敏感人群避免外出 - 轻度污染,儿童、老人、呼吸道疾病患者避免户外活动',
3: '所有人群减少外出 - 中度污染,建议减少户外活动,外出时佩戴口罩',
4: '儿童老人避免外出 - 重度污染,敏感人群应留在室内,关闭门窗',
5: '室内活动为佳 - 严重污染,所有人群避免户外活动,使用空气净化器'
},
'training_info': {
'样本数量': len(self.df),
'特征数量': len(self.X.columns),
'训练时间': pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S'),
'模型类型': 'RandomForestClassifier',
'数据来源': self.data_path
}
}
# 3.3 保存模型
joblib.dump(model_data, model_path)
print(f"✓ 模型已保存到: {model_path}")
# 3.4 保存特征范围(用于GUI滑块设置)
feature_ranges = {}
for col in self.X.columns:
feature_ranges[col] = {
'min': float(self.df[col].min()),
'max': float(self.df[col].max()),
'mean': float(self.df[col].mean()),
'std': float(self.df[col].std()),
'q1': float(self.df[col].quantile(0.25)),
'q3': float(self.df[col].quantile(0.75))
}
ranges_path = 'models/feature_ranges.json'
with open(ranges_path, 'w', encoding='utf-8') as f:
json.dump(feature_ranges, f, ensure_ascii=False, indent=2)
print(f"✓ 特征范围已保存到: {ranges_path}")
# 3.5 保存模型元数据
metadata = {
'model_info': {
'name': 'AirQualityCrowdAdviceModel',
'version': '1.0.0',
'description': '基于空气质量数据的人群外出建议模型',
'author': 'Air Quality System',
'created_date': pd.Timestamp.now().strftime('%Y-%m-%d')
},
'features': list(self.X.columns),
'classes': list(self.label_encoder.classes_),
'feature_ranges': feature_ranges
}
metadata_path = 'models/model_metadata.json'
with open(metadata_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
print(f"✓ 模型元数据已保存到: {metadata_path}")
def run_training_pipeline(self):
"""运行完整的训练流程"""
print("="*60)
print("空气质量外出建议模型训练系统")
print("="*60)
try:
# 1. 加载和预处理数据
X, y, features = self.load_and_preprocess()
# 2. 训练模型
accuracy, X_test, y_test, y_pred = self.train_model()
# 3. 保存模型
self.save_model()
print("\n" + "="*60)
print("🎉 模型训练完成!")
print(f"📊 最终准确率: {accuracy:.4f}")
print(f"🔢 特征数量: {len(features)}")
print(f"🏷️ 类别数量: {len(self.label_encoder.classes_)}")
print("="*60)
print("\n📁 生成的文件:")
print(" - models/air_quality_model.pkl (主模型文件)")
print(" - models/feature_ranges.json (特征范围)")
print(" - models/model_metadata.json (模型元数据)")
print(" - feature_importance.png (特征重要性图)")
print(" - confusion_matrix.png (混淆矩阵)")
return True
except Exception as e:
print(f"\n❌ 训练过程中出现错误: {str(e)}")
import traceback
traceback.print_exc()
return False
if __name__ == "__main__":
# 训练模型
trainer = AirQualityModelTrainer(data_path='data/cata_6716.csv')
success = trainer.run_training_pipeline()
if success:
print("\n✅ 下一步: 运行 'python predict_app.py' 启动GUI应用")
else:
print("\n❌ 训练失败,请检查数据和代码")
predict_app.py
"""
空气质量外出建议GUI应用
使用训练好的模型提供实时建议
"""
import tkinter as tk
from tkinter import ttk, messagebox, font
import joblib
import numpy as np
import json
import os
from PIL import Image, ImageTk
import pandas as pd
class AirQualityApp:
def __init__(self, root):
"""初始化GUI应用"""
self.root = root
self.root.title("空气质量外出建议系统")
self.root.geometry("1000x750")
self.root.configure(bg='#f0f8ff')
# 设置图标
try:
self.root.iconbitmap('icon.ico')
except:
pass
# 模型数据
self.model_data = None
self.model = None
self.label_encoder = None
self.scaler = None
self.feature_columns = None
self.feature_ranges = None
# 加载模型
if not self.load_model():
messagebox.showerror("错误", "无法加载模型,请先运行train_model.py训练模型")
return
# 设置样式
self.setup_styles()
# 创建界面
self.create_widgets()
def setup_styles(self):
"""设置界面样式"""
style = ttk.Style()
style.theme_use('clam')
# 自定义样式
style.configure('Title.TLabel',
font=('微软雅黑', 22, 'bold'),
background='#f0f8ff',
foreground='#1e3d59')
style.configure('Subtitle.TLabel',
font=('微软雅黑', 12),
background='#f0f8ff',
foreground='#2c3e50')
style.configure('Result.TLabel',
font=('微软雅黑', 16, 'bold'),
background='#f0f8ff',
foreground='#2c3e50')
style.configure('Advice.TLabel',
font=('微软雅黑', 13),
background='#f0f8ff',
foreground='#34495e',
wraplength=400)
style.configure('Slider.TLabel',
font=('微软雅黑', 10, 'bold'),
background='#f0f8ff',
foreground='#2c3e50')
style.configure('Value.TLabel',
font=('微软雅黑', 10),
background='#f0f8ff',
foreground='#1e3d59')
style.configure('Accent.TButton',
font=('微软雅黑', 12, 'bold'),
background='#4a90e2',
foreground='white')
def load_model(self):
"""加载训练好的模型"""
model_path = 'models/air_quality_model.pkl'
if not os.path.exists(model_path):
return False
try:
self.model_data = joblib.load(model_path)
self.model = self.model_data['model']
self.label_encoder = self.model_data['label_encoder']
self.scaler = self.model_data['scaler']
self.feature_columns = self.model_data['feature_columns']
# 加载特征范围
ranges_path = 'models/feature_ranges.json'
if os.path.exists(ranges_path):
with open(ranges_path, 'r', encoding='utf-8') as f:
self.feature_ranges = json.load(f)
print(f"✓ 模型加载成功!")
print(f"✓ 特征: {self.feature_columns}")
print(f"✓ 类别: {list(self.label_encoder.classes_)}")
return True
except Exception as e:
print(f"✗ 加载模型失败: {str(e)}")
return False
def create_widgets(self):
"""创建界面控件"""
# 主容器
main_container = ttk.Frame(self.root)
main_container.pack(fill=tk.BOTH, expand=True, padx=20, pady=20)
# 标题区域
title_frame = ttk.Frame(main_container, style='Title.TFrame')
title_frame.pack(pady=(0, 20))
title_label = ttk.Label(title_frame,
text="🌤️ 空气质量外出建议系统",
style='Title.TLabel')
title_label.pack()
subtitle_label = ttk.Label(title_frame,
text="调整污染物参数,获取针对不同人群的健康外出建议",
style='Subtitle.TLabel')
subtitle_label.pack(pady=5)
# 主内容区域
content_frame = ttk.Frame(main_container)
content_frame.pack(fill=tk.BOTH, expand=True)
# 左侧参数控制区域
control_frame = ttk.LabelFrame(content_frame, text="空气质量参数设置", padding=20)
control_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 10))
# 定义参数配置
self.param_configs = {
'细颗粒物': {
'unit': 'μg/m³',
'desc': 'PM2.5 - 直径≤2.5μm的颗粒物',
'standard': '国家标准: ≤35μg/m³',
'color': '#ff6b6b'
},
'可吸入颗粒物': {
'unit': 'μg/m³',
'desc': 'PM10 - 直径≤10μm的颗粒物',
'standard': '国家标准: ≤50μg/m³',
'color': '#4ecdc4'
},
'二氧化硫': {
'unit': 'μg/m³',
'desc': 'SO₂ - 主要来自燃煤',
'standard': '国家标准: ≤60μg/m³',
'color': '#45b7d1'
},
'二氧化氮': {
'unit': 'μg/m³',
'desc': 'NO₂ - 主要来自机动车尾气',
'standard': '国家标准: ≤40μg/m³',
'color': '#96ceb4'
},
'一氧化碳': {
'unit': 'mg/m³',
'desc': 'CO - 无色无味有毒气体',
'standard': '国家标准: ≤4mg/m³',
'color': '#feca57'
},
'臭氧1小时平均': {
'unit': 'μg/m³',
'desc': 'O₃ - 光化学烟雾主要成分',
'standard': '国家标准: ≤160μg/m³',
'color': '#ff9ff3'
}
}
# 存储滑块和变量
self.sliders = {}
self.slider_vars = {}
# 创建滑块
for i, param in enumerate(self.feature_columns):
if param not in self.param_configs:
continue
config = self.param_configs[param]
# 获取范围
if self.feature_ranges and param in self.feature_ranges:
min_val = int(self.feature_ranges[param]['min'])
max_val = int(self.feature_ranges[param]['max'] * 1.2) # 留有余量
default_val = int(self.feature_ranges[param]['mean'])
else:
# 默认范围
ranges = {
'细颗粒物': (0, 500, 50),
'可吸入颗粒物': (0, 600, 70),
'二氧化硫': (0, 200, 20),
'二氧化氮': (0, 300, 30),
'一氧化碳': (0, 10, 1),
'臭氧1小时平均': (0, 500, 50)
}
min_val, max_val, default_val = ranges.get(param, (0, 100, 50))
# 参数框架
param_frame = ttk.Frame(control_frame)
param_frame.pack(fill=tk.X, pady=(0, 15))
# 参数标签
label_frame = ttk.Frame(param_frame)
label_frame.pack(fill=tk.X, pady=(0, 5))
ttk.Label(label_frame,
text=f"{param} ({config['unit']})",
style='Slider.TLabel').pack(side=tk.LEFT)
ttk.Label(label_frame,
text=config['desc'],
font=('微软雅黑', 8),
foreground='#7f8c8d').pack(side=tk.LEFT, padx=(10, 0))
# 滑块和数值显示框架
slider_frame = ttk.Frame(param_frame)
slider_frame.pack(fill=tk.X)
# 数值显示
var = tk.DoubleVar(value=default_val)
value_label = ttk.Label(slider_frame,
textvariable=var,
style='Value.TLabel',
width=8)
value_label.pack(side=tk.RIGHT, padx=(10, 0))
# 单位标签
ttk.Label(slider_frame,
text=config['unit'],
font=('微软雅黑', 9),
foreground='gray').pack(side=tk.RIGHT)
# 滑块
slider = ttk.Scale(slider_frame,
from_=min_val,
to=max_val,
orient=tk.HORIZONTAL,
length=350,
variable=var,
command=lambda v, p=param: self.on_slider_change(p, v))
slider.pack(side=tk.LEFT, fill=tk.X, expand=True)
# 国家标准显示
std_label = ttk.Label(param_frame,
text=f"📊 {config['standard']}",
font=('微软雅黑', 8),
foreground='#27ae60')
std_label.pack(anchor='w', pady=(2, 0))
# 存储引用
self.sliders[param] = slider
self.slider_vars[param] = var
# 控制按钮区域
button_frame = ttk.Frame(control_frame)
button_frame.pack(fill=tk.X, pady=(20, 0))
# 预测按钮
predict_btn = ttk.Button(button_frame,
text="🚀 获取外出建议",
style='Accent.TButton',
command=self.predict)
predict_btn.pack(side=tk.LEFT, expand=True, fill=tk.X, padx=(0, 10))
# 重置按钮
reset_btn = ttk.Button(button_frame,
text="🔄 重置参数",
command=self.reset_sliders)
reset_btn.pack(side=tk.LEFT, expand=True, fill=tk.X)
# 右侧结果显示区域
result_frame = ttk.LabelFrame(content_frame, text="外出建议", padding=20)
result_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True, padx=(10, 0))
# 结果展示区域
self.result_text = tk.Text(result_frame,
height=12,
width=40,
font=('微软雅黑', 12),
wrap=tk.WORD,
bg='#f8f9fa',
fg='#2c3e50',
relief=tk.FLAT,
borderwidth=2)
self.result_text.pack(fill=tk.BOTH, expand=True, pady=(0, 15))
# 设置初始提示文本
initial_text = """🔍 请调整左侧的污染物参数滑块,然后点击"获取外出建议"按钮。
系统将根据当前的空气质量参数,为您提供针对不同人群的健康外出建议。
📊 参数说明:
• 细颗粒物(PM2.5): 可入肺颗粒物,健康危害大
• 可吸入颗粒物(PM10): 可进入呼吸道的颗粒物
• 二氧化硫(SO₂): 刺激性气体,主要来自燃煤
• 二氧化氮(NO₂): 刺激性气体,主要来自机动车
• 一氧化碳(CO): 无色无味有毒气体
• 臭氧(O₃): 光化学烟雾主要成分
💡 提示:绿色标注为国家标准限值。"""
self.result_text.insert(1.0, initial_text)
self.result_text.config(state=tk.DISABLED)
# 详细建议框架
detail_frame = ttk.LabelFrame(result_frame, text="详细健康建议", padding=15)
detail_frame.pack(fill=tk.BOTH, expand=True)
self.detail_text = tk.Text(detail_frame,
height=8,
font=('微软雅黑', 11),
wrap=tk.WORD,
bg='#f8f9fa',
fg='#34495e',
relief=tk.FLAT)
self.detail_text.pack(fill=tk.BOTH, expand=True)
# 设置初始详细建议
detail_initial = """👥 适用人群分类:
• 全部人群:健康成年人
• 敏感人群:儿童、老人、孕妇、呼吸道疾病患者
• 特殊人群:心脏病、哮喘等慢性病患者
🛡️ 防护建议等级:
• ✅ 适宜外出:无需特殊防护
• ⚠️ 减少外出:减少户外时间
• 🚫 避免外出:尽量留在室内
• 🏠 室内活动:关闭门窗,使用空气净化器"""
self.detail_text.insert(1.0, detail_initial)
self.detail_text.config(state=tk.DISABLED)
# 状态栏
status_frame = ttk.Frame(main_container, relief=tk.SUNKEN, borderwidth=1)
status_frame.pack(fill=tk.X, pady=(10, 0))
self.status_label = ttk.Label(status_frame,
text="就绪 | 模型已加载 | 等待输入参数",
font=('微软雅黑', 9),
foreground='#7f8c8d')
self.status_label.pack(side=tk.LEFT, padx=5)
def on_slider_change(self, param, value):
"""滑块变化回调"""
# 更新状态栏
self.status_label.config(text=f"调整: {param} = {float(value):.1f}")
def reset_sliders(self):
"""重置所有滑块到默认值"""
for param, slider in self.sliders.items():
if self.feature_ranges and param in self.feature_ranges:
default_val = self.feature_ranges[param]['mean']
else:
default_val = 50
self.slider_vars[param].set(default_val)
# 清空结果显示
self.result_text.config(state=tk.NORMAL)
self.result_text.delete(1.0, tk.END)
self.result_text.insert(1.0, "参数已重置,请重新获取建议")
self.result_text.config(state=tk.DISABLED)
self.detail_text.config(state=tk.NORMAL)
self.detail_text.delete(1.0, tk.END)
self.detail_text.insert(1.0, "等待新的预测结果...")
self.detail_text.config(state=tk.DISABLED)
self.status_label.config(text="参数已重置 | 等待输入")
def predict(self):
"""进行预测并显示结果"""
if self.model is None:
messagebox.showerror("错误", "模型未加载,无法进行预测")
return
try:
# 1. 获取当前参数值
features = []
for param in self.feature_columns:
value = self.slider_vars[param].get()
features.append(value)
# 2. 转换为numpy数组并标准化
X = np.array([features], dtype=np.float32)
X_scaled = self.scaler.transform(X)
# 3. 进行预测
prediction = self.model.predict(X_scaled)[0]
probability = self.model.predict_proba(X_scaled)[0]
# 4. 解码预测结果
label = self.label_encoder.inverse_transform([prediction])[0]
# 5. 获取预测概率
prob_dict = {}
for i, cls in enumerate(self.label_encoder.classes_):
prob_dict[cls] = probability[i] * 100
# 6. 显示结果
self.display_result(label, prob_dict, features)
# 7. 更新状态
self.status_label.config(text=f"预测完成: {label} | 置信度: {probability[prediction]*100:.1f}%")
except Exception as e:
messagebox.showerror("预测错误", f"预测过程中出现错误:\n{str(e)}")
self.status_label.config(text="预测失败")
def display_result(self, label, probabilities, features):
"""显示预测结果"""
# 结果颜色映射
color_map = {
'全部人群适宜外出': '#27ae60', # 绿色
'敏感人群减少外出': '#f39c12', # 橙色
'敏感人群避免外出': '#e74c3c', # 红色
'所有人群减少外出': '#c0392b', # 深红
'儿童老人避免外出': '#8e44ad', # 紫色
'室内活动为佳': '#2c3e50' # 深灰
}
# 图标映射
icon_map = {
'全部人群适宜外出': '✅',
'敏感人群减少外出': '⚠️',
'敏感人群避免外出': '🚫',
'所有人群减少外出': '🔴',
'儿童老人避免外出': '🟣',
'室内活动为佳': '🏠'
}
# 详细建议映射
advice_map = {
'全部人群适宜外出': """✅ 健康建议:
• 所有人群可正常进行户外活动
• 适合跑步、骑行、球类等各类运动
• 无需特殊防护措施
• 建议开窗通风,保持室内空气流通
🎯 适用人群:
• 健康成年人
• 儿童和老人
• 孕妇
• 呼吸道疾病患者""",
'敏感人群减少外出': """⚠️ 健康建议:
• 敏感人群应减少长时间、高强度的户外活动
• 健康人群可正常活动,但避免剧烈运动
• 外出时可考虑佩戴口罩
• 建议减少开窗时间
🎯 敏感人群包括:
• 儿童、老人、孕妇
• 哮喘、支气管炎患者
• 心脏病、高血压患者
• 过敏体质者""",
'敏感人群避免外出': """🚫 健康建议:
• 敏感人群应尽量避免户外活动
• 健康人群减少户外活动时间
• 必须外出时请佩戴防护口罩
• 关闭门窗,使用空气净化器
• 避免晨练等户外运动
🏥 重点关注:
• 儿童和老人尽量留在室内
• 呼吸道疾病患者避免外出
• 学校减少户外体育课""",
'所有人群减少外出': """🔴 健康建议:
• 所有人群均应减少户外活动
• 避免长时间停留在室外
• 外出必须佩戴有效防护口罩
• 关闭门窗,开启空气净化
• 取消户外活动和集会
🛡️ 防护措施:
• N95/KN95级别口罩
• 尽量减少户外停留时间
• 回家后及时清洗面部和鼻腔""",
'儿童老人避免外出': """🟣 健康建议:
• 儿童、老人、孕妇务必留在室内
• 健康成人尽量减少不必要外出
• 必须外出时做好全面防护
• 学校应停止所有户外活动
• 养老院、幼儿园加强防护
👶 特殊保护:
• 儿童免疫力较低,易受影响
• 老人呼吸系统脆弱,风险高
• 慢性病患者需格外注意""",
'室内活动为佳': """🏠 健康建议:
• 所有人群应避免户外活动
• 尽量留在室内,关闭门窗
• 必须外出时做好最高级别防护
• 使用高效空气净化器
• 避免所有户外运动和活动
🚨 紧急措施:
• 尽量减少外出,远程办公/学习
• 外出佩戴专业防护设备
• 密切关注健康状况
• 如有不适及时就医"""
}
# 获取颜色和图标
color = color_map.get(label, '#2c3e50')
icon = icon_map.get(label, '📊')
# 构建结果显示文本
result_content = f"""{icon} 【外出建议】{icon}
{label}
📈 预测置信度: {probabilities[label]:.1f}%
📊 所有可能性:
"""
# 按概率排序
sorted_probs = sorted(probabilities.items(), key=lambda x: x[1], reverse=True)
for cls, prob in sorted_probs:
if prob > 1: # 只显示概率大于1%的类别
result_content += f" • {cls}: {prob:.1f}%\n"
result_content += f"\n🔢 当前参数值:\n"
for param, value in zip(self.feature_columns, features):
result_content += f" • {param}: {value:.1f}\n"
# 更新结果文本框
self.result_text.config(state=tk.NORMAL)
self.result_text.delete(1.0, tk.END)
self.result_text.insert(1.0, result_content)
# 设置标题颜色
self.result_text.tag_add("title", "1.0", "3.0")
self.result_text.tag_config("title", foreground=color, font=('微软雅黑', 14, 'bold'))
self.result_text.config(state=tk.DISABLED)
# 更新详细建议
self.detail_text.config(state=tk.NORMAL)
self.detail_text.delete(1.0, tk.END)
self.detail_text.insert(1.0, advice_map.get(label, "暂无详细建议"))
self.detail_text.config(state=tk.DISABLED)
def main():
"""主函数"""
root = tk.Tk()
app = AirQualityApp(root)
# 设置窗口居中
root.update_idletasks()
width = root.winfo_width()
height = root.winfo_height()
x = (root.winfo_screenwidth() // 2) - (width // 2)
y = (root.winfo_screenheight() // 2) - (height // 2)
root.geometry(f'{width}x{height}+{x}+{y}')
# 设置最小窗口大小
root.minsize(900, 600)
root.mainloop()
if __name__ == "__main__":
main()
此处为Readme展示(由AI生成):
空气质量外出建议系统(readme.md始)
基于机器学习的空气质量分析与人群健康建议系统,可根据污染物浓度预测适宜外出人群。
功能特点
- 数据分析:对历史空气质量数据进行深入分析
- 模型训练:使用随机森林算法训练预测模型
- 实时预测:通过GUI界面实时调整参数获取建议
- 健康建议:针对不同人群提供详细外出建议
- 可视化:生成特征重要性、混淆矩阵等分析图表
快速开始
1. 环境配置
bash
克隆或下载项目
git clone
cd air_quality_system
创建虚拟环境(推荐)
python -m venv venv
激活虚拟环境
Windows:
venv\Scripts\activate
Linux/Mac:
source venv/bin/activate
安装依赖
pip install -r requirements.txt
2. 准备数据
- 将您的空气质量数据CSV文件(如
cata_6716.csv)放入data/目录 - 确保数据包含以下字段(或类似字段):
- 细颗粒物 (PM2.5)
- 可吸入颗粒物 (PM10)
- 二氧化硫 (SO2)
- 二氧化氮 (NO2)
- 一氧化碳 (CO)
- 臭氧1小时平均 (O3)
- 空气质量指数 (AQI)
3. 训练模型
bash
python train_model.py
训练过程将:
- 加载并预处理数据
- 训练随机森林模型
- 评估模型性能
- 保存模型到
models/目录 - 生成可视化图表
4. 使用GUI应用
bash
python predict_app.py
文件结构
air_quality_system/
├── train_model.py # 模型训练脚本
├── predict_app.py # GUI应用界面
├── data/ # 数据目录
│ └── cata_6716.csv # 空气质量数据
├── models/ # 模型保存目录
│ ├── air_quality_model.pkl # 训练好的模型
│ ├── feature_ranges.json # 特征范围
│ └── model_metadata.json # 模型元数据
├── requirements.txt # Python依赖
├── README.md # 项目说明
├── feature_importance.png # 特征重要性图
└── confusion_matrix.png # 混淆矩阵
模型说明
算法
- 使用随机森林分类器
- 特征标准化处理
- 类别平衡处理
- 交叉验证评估
预测类别
系统可预测6种外出建议:
- ✅ 全部人群适宜外出
- ⚠️ 敏感人群减少外出
- 🚫 敏感人群避免外出
- 🔴 所有人群减少外出
- 🟣 儿童老人避免外出
- 🏠 室内活动为佳
GUI界面功能
- 参数调节:6个污染物浓度滑块
- 实时预测:点击获取实时建议
- 结果展示:预测结果和置信度
- 详细建议:针对不同人群的健康建议
- 参数重置:一键重置所有参数
技术细节
特征工程
- 特征标准化:使用StandardScaler
- 特征选择:基于重要性排序
- 标签编码:使用LabelEncoder
模型评估
- 准确率、精确率、召回率、F1分数
- 混淆矩阵分析
- 特征重要性分析
数据预处理
- 缺失值处理
- 异常值检测
- 特征范围规范化
自定义配置
修改特征
在train_model.py中修改feature_columns列表:
python
feature_columns = [
‘细颗粒物’, # PM2.5
‘可吸入颗粒物’, # PM10
‘二氧化硫’, # SO2
‘二氧化氮’, # NO2
‘一氧化碳’, # CO
‘臭氧1小时平均’ # O3
]
调整模型参数
在train_model.py中修改RandomForestClassifier参数:
python
self.model = RandomForestClassifier(
n_estimators=200, # 树的数量
max_depth=15, # 树的最大深度
min_samples_split=5, # 分裂所需最小样本数
min_samples_leaf=2, # 叶节点最小样本数
random_state=42, # 随机种子
class_weight=’balanced’ # 类别权重
)
注意事项
- 数据质量:确保输入数据质量,缺失值和异常值会影响模型性能
- 模型更新:建议定期用新数据重新训练模型
- 地域差异:不同地区的空气质量特征可能不同
- 实时性:模型基于历史数据,实时预测需结合实时监测
故障排除
常见问题
- 编码错误:如果CSV文件读取失败,尝试修改编码
python
在train_model.py中修改
self.df = pd.read_csv(self.data_path, encoding=’gbk’) # 或’utf-8′
- 缺少特征:检查数据文件是否包含所有必要特征
- 内存不足:减少树的数量或调整其他参数
- GUI启动失败:确保已安装所有依赖,特别是tkinter
错误日志
查看控制台输出获取详细错误信息,日志包含:
- 数据处理状态
- 模型训练进度
- 评估结果
- 文件保存位置
扩展功能
计划中的功能
- 多城市数据支持
- 时间序列预测
- 移动端应用
- 数据自动更新
- 多语言支持
自定义扩展
您可以通过以下方式扩展系统:
- 添加新的污染物特征
- 调整健康建议标准
- 集成实时数据API
- 添加更多可视化图表
许可证
本项目仅供学习和研究使用。
技术支持
如有问题或建议,请:
- 检查错误日志
- 参考代码注释
- 确保环境配置正确
- 验证数据格式
开始使用:按照”快速开始”步骤操作,几分钟内即可运行完整系统!
三、使用步骤
步骤1:创建项目结构
创建项目目录
mkdir air_quality_system
cd air_quality_system
创建子目录
mkdir data
mkdir models
创建代码文件
将上面的代码分别保存为对应的文件:
train_model.py
predict_app.py
requirements.txt
README.md
步骤2:放置数据文件
将您的 cata_6716.csv文件放入 data/目录
步骤3:安装依赖
pip install -r requirements.txt
步骤4:训练模型
python train_model.py
步骤5:运行GUI应用
python predict_app.py
四、注意事项
编码问题:您的CSV文件是GBK编码,代码中已处理
特征对应:确保您的数据列名与代码中的特征名匹配
路径正确:确保数据文件在正确路径 data/cata_6716.csv
依赖安装:如果tkinter有问题,可能需要安装系统级的tkinter包
模型保存:训练完成后会在models目录生成多个文件这个完整的代码包可以直接使用,包含了数据处理、模型训练、GUI界面等所有功能。训练完成后,您可以通过GUI界面实时调整污染物参数,获取针对不同人群的健康外出建议。
 本文采用 CC BY-NC-SA 4.0 国际 许可协议 进行许可。
转载请注明作者及原文链接,并遵循相同方式共享原则。
链接:
本文采用 CC BY-NC-SA 4.0 国际 许可协议 进行许可。
转载请注明作者及原文链接,并遵循相同方式共享原则。
链接:

头发掉光光
六六六还当上四人博客了
公共场合别乱说话
So clever ! You are son of beach !
你好